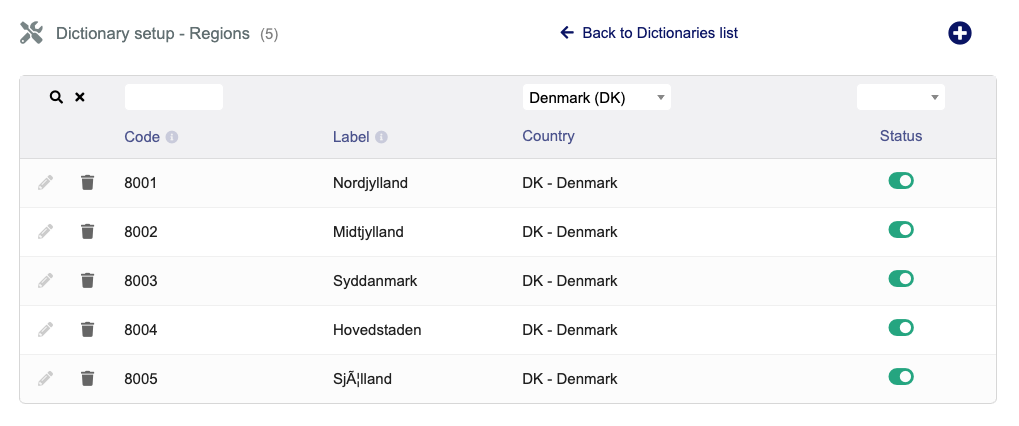
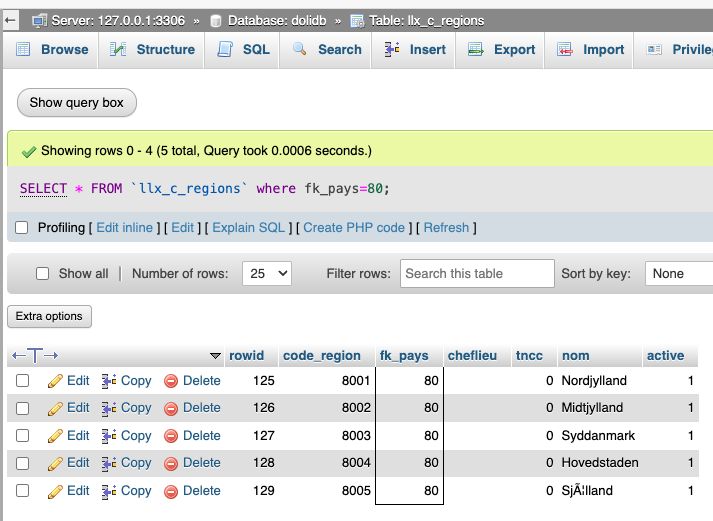
which the help of lumo I tracked it down and have possibly fixed it
I see the issue now. The CONVERT method doesn't work because MariaDB validates the UTF-8 bytes before conversion. The bytes C3 83 C2 A6 are valid UTF-8 (they spell "æ"), so MariaDB doesn't see them as corrupted.
We need to use raw byte manipulation with HEX() and UNHEX() to fix the double-encoding. This bypasses all character set validation.
The Working Fix: Hex Replacement Method
Run these commands in order in your MariaDB container:
Step 1: Change Column to Binary (Bypass Charset Validation)
ALTER TABLE llx_c_regions MODIFY nom VARBINARY(255);
This converts the column to raw bytes without any character set interpretation.
Step 2: Replace the Double-Encoded Bytes
UPDATE llx_c_regions
SET nom = UNHEX(REPLACE(HEX(nom), 'C383C2A6', 'C3A6'))
WHERE code_region = 8005;
How this works:
HEX(nom) converts the bytes to hex string: 536AC383C2A66C6C616E64
REPLACE(..., 'C383C2A6', 'C3A6') replaces the double-encoded æ with correct æ
UNHEX(...) converts back to raw bytes: 536AC3A66C6C616E64
Step 3: Change Column Back to UTF-8
ALTER TABLE llx_c_regions MODIFY nom VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Step 4: Verify
SELECT nom, HEX(nom), LENGTH(nom), CHAR_LENGTH(nom)
FROM llx_c_regions
WHERE code_region = 8005;
Expected Output:
nom HEX(nom) LENGTH CHAR_LENGTH
Sjælland 536AC3A66C6C616E64 10 9
Notice:
LENGTH should drop from 11 → 10
HEX should show C3A6 instead of C383C2A6
Fix All Affected Columns
Once this works, you can fix all other double-encoded columns with this script:
-- Generate fix commands for all text columns
SELECT CONCAT(
'ALTER TABLE `', table_name, '` MODIFY `', column_name, '` VARBINARY(', CHARACTER_MAXIMUM_LENGTH, '); ',
'UPDATE `', table_name, '` SET `', column_name, '` = UNHEX(REPLACE(HEX(`', column_name, '`), ''C383C2A6'', ''C3A6'')); ',
'UPDATE `', table_name, '` SET `', column_name, '` = UNHEX(REPLACE(HEX(`', column_name, '`), ''C383C2B8'', ''C3B8'')); ',
'UPDATE `', table_name, '` SET `', column_name, '` = UNHEX(REPLACE(HEX(`', column_name, '`), ''C383C2A5'', ''C3A5'')); ',
'ALTER TABLE `', table_name, '` MODIFY `', column_name, '` VARCHAR(', CHARACTER_MAXIMUM_LENGTH, ') CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;'
) as fix_commands
FROM information_schema.columns
WHERE table_schema = 'dolidb'
AND data_type IN ('varchar', 'text', 'mediumtext', 'longtext')
AND character_set_name = 'utf8mb4';
Common Danish double-encoding patterns to fix:
Display Hex (Wrong) Hex (Correct) Character
æ C383C2A6 C3A6 æ
ø C383C2B8 C3B8 ø
Ã¥ C383C2A5 C3A5 å
Æ C383C286 C386 Æ
Ø C383C298 C398 Ø
Ã… C383C285 C385 Å
Important: Prevent Future Corruption
After fixing the data, you must add the LANG environment variable to your Dolibarr container, or new data will get corrupted again.
Edit docker-compose.yml:
services:
dolibarr:
image: dolibarr/dolibarr:23.0.0
environment:
- LANG=en_US.UTF-8
- LC_ALL=en_US.UTF-8
- LC_CTYPE=en_US.UTF-8
# ... rest of config
Restart:
docker compose up -d --force-recreate dolibarr
Try the Hex Replacement Now
Run the 3-step fix (VARBINARY → REPLACE → VARCHAR) and let me know if the hex changes to 536AC3A66C6C616E64! This is the most reliable method for fixing double-encoded UTF-8 data in MariaDB.
Regenerate
YES, this last step worked :-)
I also need to make my demo dolibarr use the right locale in the container.